

I’m Rishabh, Lead Data Engineer based in Seattle, WA, USA. I have extensive experience in Developing Big Data pipelines and working on cloud ecosystems. I am also good at Data Warehousing, ETL Development and writing scalable code.
I love playing with data, finding insights by creating Data pipelines and handling end to end Big Data systems.
With experience working in different cloud technologies, it's my passion to develop and architect robust cloud ecosystems by following best practices.
Building AI-driven data products by integrating LLMs and machine learning into data pipelines. Experienced in prompt engineering, embedding-based search, and shipping intelligent features on top of cloud-native data platforms.
System that evaluates an investment decision taking into account the stock’s historical performance, global news sentiment and company’s Edgar reports.
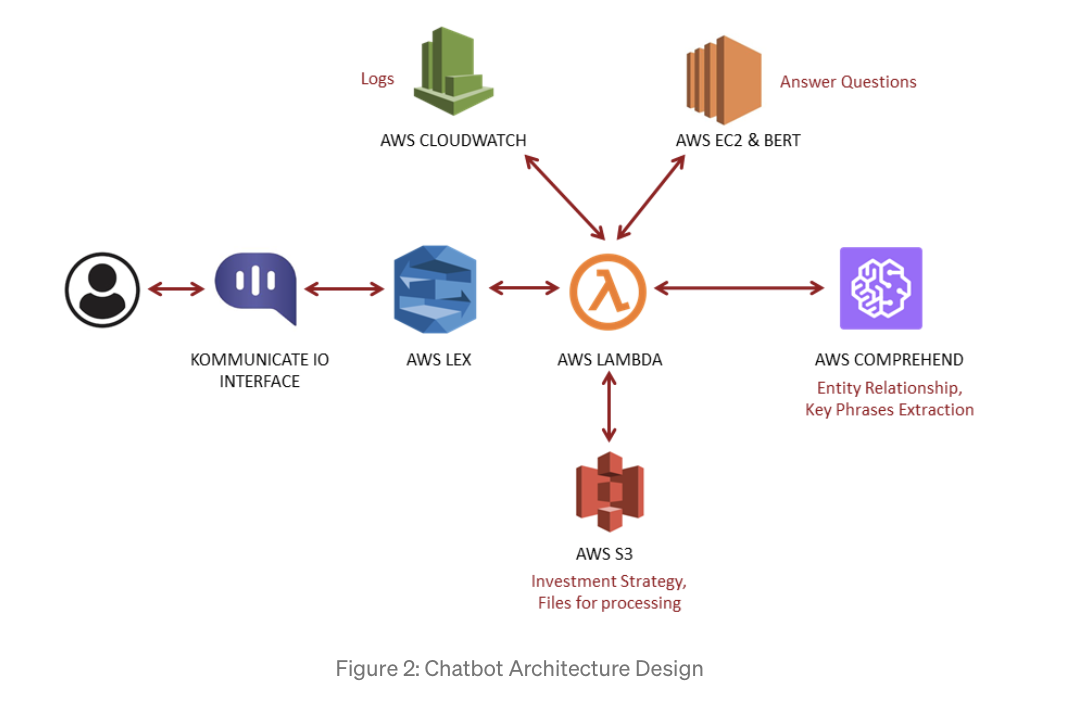
Architecture of the Chabot designed as part of the project.
This project is aimed to act as an interactive assistant to humans to achieve tasks. There is a speech conversation with the system to command the system to detect objects in a live video feed.
The user issues the wake up command to pass object name as speech and the systems returns a bounding box and speech feedback regarding the presence of the object.
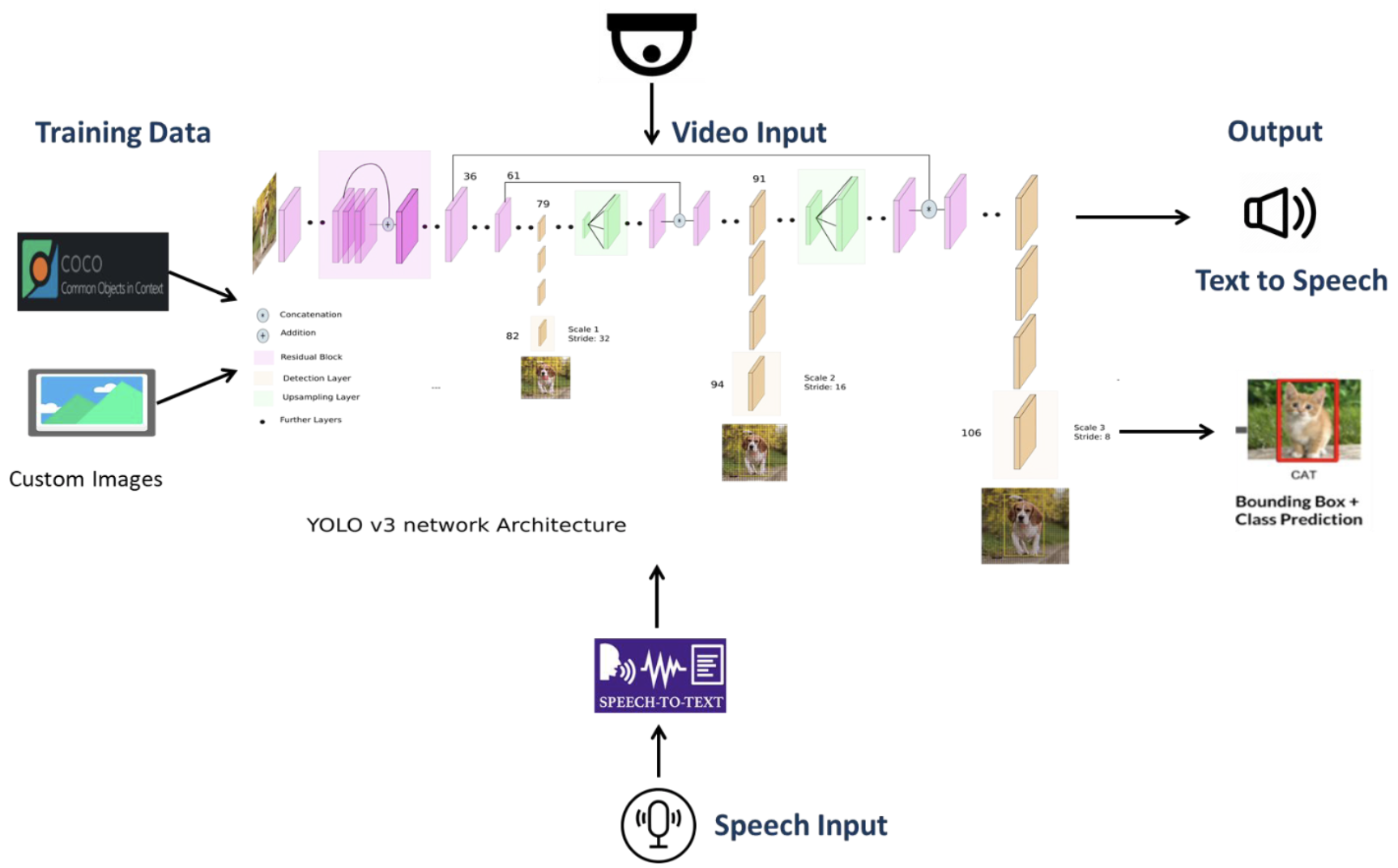
The application continues to look in a live webcam feed generated through OpenCV. In parallel, post a wakeup command, a text input is passed to the system and converted to text using Speech Recognizer.
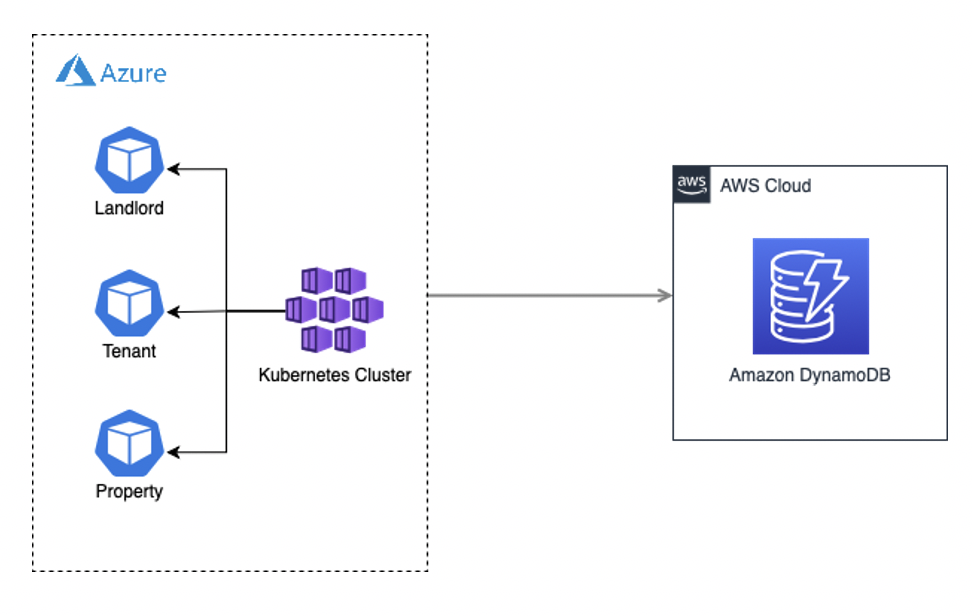
- Find Your Home is an online platform that enables landlords and their tenants to gain a common consensus and enhance transparency. A landlord would want to list and publicize his properties, manage his tenants and attend to service requests to ensure meeting his side of the deal. On the other hand, a potential tenant would want to find and compare properties or raise service requests in their existing property.
Our solution aims to simplify the interactions amongst tenants, landlords and their properties by bringing them into a common domain and establishing a relationship that alleviates this plethora of problems making the pipe-dream a reality.
All variations are organized separately so you can use / customize the template very easily.
A full-stack portfolio tracker supporting stocks, ETFs, mutual funds, crypto, and cash across Canadian, US, and Indian brokers. Upload broker exports (Wealthsimple, Questrade, Zerodha) or connect live via SnapTrade (CA/US) or Kite Connect (Zerodha India).

Folio — multi-broker portfolio tracker with live broker connections, ETF look-through, and a 30-year growth forecast engine.
John is a hotel manager and is given the task for forecasting the room bookings for the next season so that the hotel can make staff and inventory available.
Read More
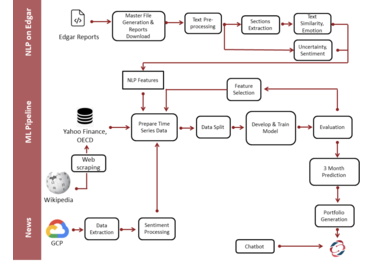
Financial markets investment decisions are more than just crunching numbers. It is tough for the majority of us without any formal training to gain the necessary information to make investment decisions.
Read More









{kind=link}
{kind=link}